Developer Creates Infinite Maze That Traps AI Training Bots
Developer Creates Infinite Maze That Traps AI Training Bots
"Nepenthes generates random links that always point back to itself - the crawler downloads those new links. Nepenthes happily just returns more and more lists of links pointing back to itself."

A pseudonymous coder has created and released an open source “tar pit” to indefinitely trap AI training web crawlers in an infinitely, randomly-generating series of pages to waste their time and computing power. The program, called Nepenthes after the genus of carnivorous pitcher plants which trap and consume their prey, can be deployed by webpage owners to protect their own content from being scraped or can be deployed “offensively” as a honeypot trap to waste AI companies’ resources.
“It's less like flypaper and more an infinite maze holding a minotaur, except the crawler is the minotaur that cannot get out. The typical web crawler doesn't appear to have a lot of logic. It downloads a URL, and if it sees links to other URLs, it downloads those too. Nepenthes generates random links that always point back to itself - the crawler downloads those new links. Nepenthes happily just returns more and more lists of links pointing back to itself,” Aaron B, the creator of Nepenthes, told 404 Media.
This showed up on HN recently. Several people who wrote web crawlers pointed out that this won’t even come close to working except on terribly written crawlers. Most just limit the number of pages crawled per domain based on popularity of the domain. So they’ll index all of Wikipedia but they definitely won’t crawl all 1 million pages of your unranked website expecting to find quality content.
Can confirm, I have a website (https://2009scape.org/) with tonnes of legacy forum posts (100k+). No crawlers ever go there.
It's a shame that 404media didn't do any due diligence when writing this
This reminds me of that one time a guy figured out how to make "gzip bombs" that bricked automated vuln scanners.
More accurately, it traps any web crawler, including regular search engines and benign projects like the Internet Archive. This should not be used without an allowlist for known trusted crawlers at least.

I haven't seen that episode in probably 15 years and I still remember exactly what this was.
First thing that popped into my head after I read the headline!
This sort of thing has been a strategy for dealing with unwanted web crawlers since web crawlers were a thing. It's an arms race, though; crawlers do things to detect these "mazes" and so the maze-makers keep needing to up their game as well.
As we enter an age where AI is effectively passing the Turing Test, it's going to be tricky making traps for them that don't also ensnare the actual humans you're trying to serve pages to.
My new favorite is asking if it's cheating to look at your opponent's pieces in chess.
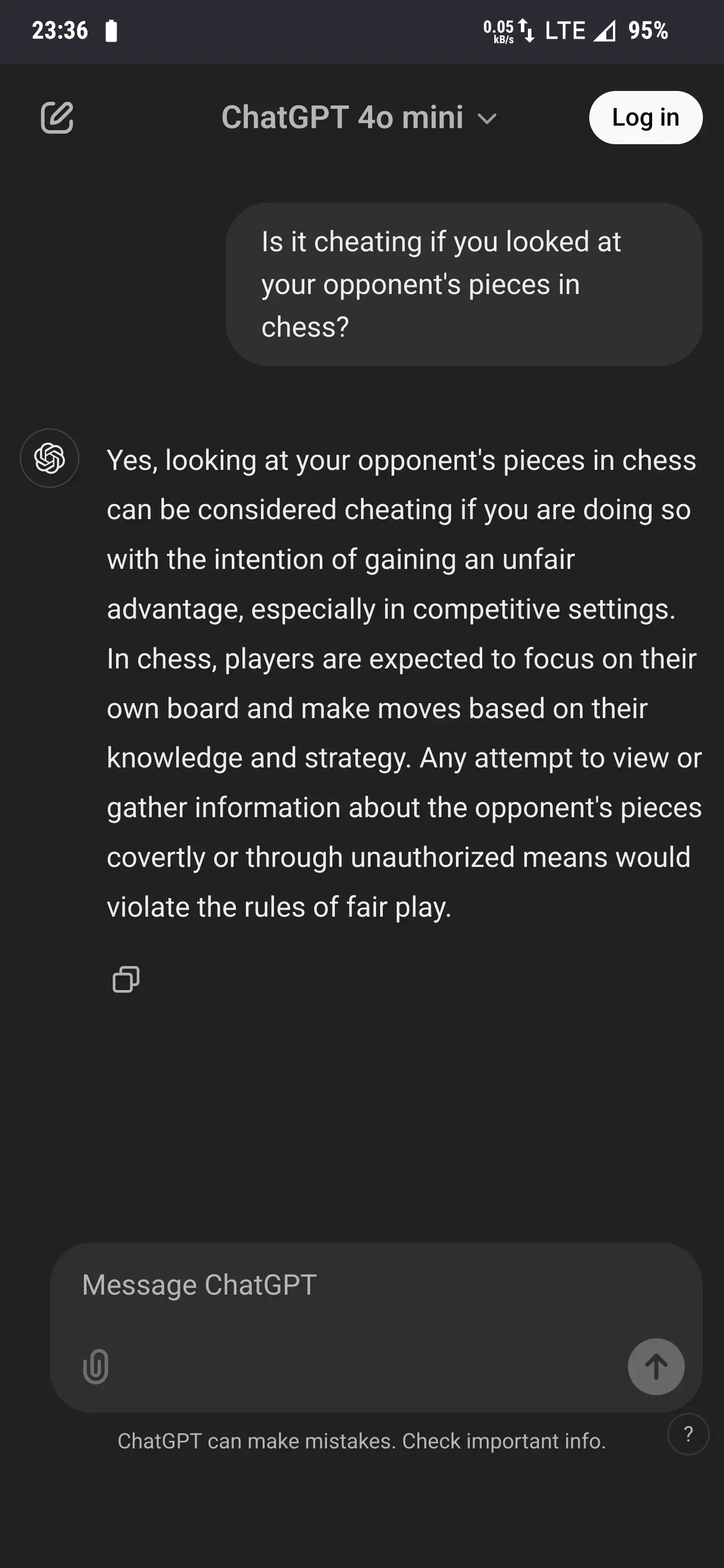
Wow lol!
This is old.
Chatgpt no longer answers like this, if it ever did.
But does running this cost the AI bot at least as much as it costs you to run?
Picking words at random from a dictionary would not be very compute intensive, the content doesn't need to be sensical
I was thinking exactly that, generating something like lorem ipsum to cost both time, compute and storage for the crawler.
It will be more complex and require more resources tho.
I would think yes. The compute needed to make a hyperlink maze is low, compared to the AI processing of the random content, which costs nearly nothing to make, but still costs the same to process as genuine content.
Am I missing something?
I'm wondering about the cost to the server's resources / bandwidth to serve up unlimited random junk also.
But kudos to the developer for making this anyway
It does if you use AI to generate the pages it's scraping.
This won't work against commercial crawlers. They check page contents with something similar to a simhash and don't recrawl these pages. They also have limiters like for depth to avoid getting stuck in circular links.
You could generate random content for each new page, but you'll still eventually hit the depth limit. There are probably other rules related to content quality to limit crawling too.
True, this is an arms race situation after all. The real benefit of this is creating garbage training data that makes garbage models. So it’s not just increasing the cost of crawling, it increases the cost of stealing everybody’s shit because you need extra data quality checks. Poisoning the well.
This genus named genius game is sending pain to these previous devious data devourors
The modern equivalent of making a page that loads in two frames, left and right, which each load in two frames, top and bottom, which each load in two frames, left and right ...
As I recall, this was five lines of HTML.
This is really nostalgic for me. I can see the Netscape throbber in my mind.
I remember making one of those.
It had a faux URL bar at the top of both the left and right frame and used a little JavaScript to turn each side into its own functioning browser window. This was long before browser tabs were a mainstream thing. At the time, relatively small 4:3 or 5:4 ratio monitors were the norm, and I couldn't bear the skinny page rendering at each side, so I gave it up as a failed experiment.
And yes I did open it inside itself. The loaded pages were even more ridiculously skinny.
When I did my five lines, recursively opening frames inside frames ad infinitum, it would crash browsers of the time in a matter of twenty seconds.