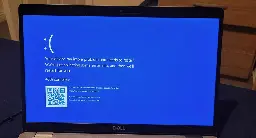
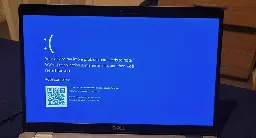
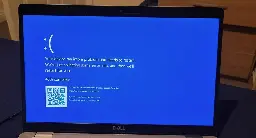
To Fix CrowdStrike Blue Screen of Death Simply Reboot 15 Straight Times, Microsoft Says
To Fix CrowdStrike Blue Screen of Death Simply Reboot 15 Straight Times, Microsoft Says
www.404media.co
To Fix CrowdStrike Blue Screen of Death Simply Reboot 15 Straight Times, Microsoft Says