Full scan of 1 cubic millimeter of brain tissue took 1.4 petabytes of data, equivalent to 14,000 4K movies — Google's AI experts assist researchers
Full scan of 1 cubic millimeter of brain tissue took 1.4 petabytes of data, equivalent to 14,000 4K movies — Google's AI experts assist researchers
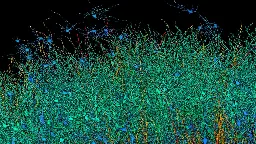
"We did the back-of-napkin math on what ramping up this experiment to the entire brain would cost, and the scale is impossibly large — 1.6 zettabytes of storage costing $50 billion and spanning 140 acres, making it the largest data center on the planet."
Look at what they need to mimic just a fraction of our power.
It’s not even complete. You might have the physical brain tissue, but that tissue is stateful. The tissue contains potentials and electrical charges that must be included in a complete model.
it's not like human brain memory or consciousness is that information dense. They just did that high of a definition of a scan.
And the whole human body, brain and all, can run on ~100 watts. Truly astounding.
And we get these 100W from transforming food that we find on/in the ground.
Shouldn't be long and we will have that much in our phones.
CERN datacenter has 1600 times less capacity
https://home.cern/news/news/computing/exabyte-disk-storage-cern
Although global storage capacity will be 125 times higher by 2025 than whole scan would occupy
https://cybersecurityventures.com/the-world-will-store-200-zettabytes-of-data-by-2025/
Sort of makes you realize how daunting self driving cars are.
That’s capturing everything. Ultimately you need only a tiny fraction of that data to emulate the human brain.
Numenta is working on a brain model to create functional sections of the brain. Their approach is different though. They are trying to understand the components and how they work together and not just aggregating vast amounts of data.
No it does not. It captures only the physical structures. There’s also chemical and electrical state that’s missing.
Think of this:
You find a computer from 1990. You take a picture (image) of the 1KB memory chip which is on a RAM stick, there are 4 RAM sticks. You are using a DSLR camera. Your image in RAW comes out at 1GB. You project because there's 8 chips per stick, and 4 sticks it'll 32GB to image your 4KB of RAM.
You've described nothing about the ram. This measurement is meaningless other than telling you how detailed the imaging process is.
Of course, not to say the data isn't also important though. It's very possible that we're missing something crucial regarding how the brain functions, despite everything we know so far. The more data we have, the better we can build/test these more streamlined models.
These models would likely be tested against these real datasets, so they help each other.
Ultimately you need only a tiny fraction of that data to emulate the human brain.
I am curious how that conclusion was formed as we have only recently discovered many new types of functional brain cells.
While I am not saying this is the case, that statement sounds like it was based on the "we only use 10% of our brain" myth, so that is why I am trying to get clarification.
They took imaging scans, I just took a picture of a 1MB memory chip and omg my picture is 4GB in RAW. That RAM the chip was on could take dozens of GB!
Not taking a position on this, but I could see a comparison with doing an electron scan of a painting. The scan would take an insane amount of storage while the (albeit ultra high definition) picture would fit on a Blu-ray.
Oh I’m not basing that on the 10% mumbo jumbo, just that data capture usually over captures. Distilling it down to just the bare functional essence will result in a far smaller data set. Granted, as you noted, there are new neuron types still being discovered, so what to discard is the question.
I don't think any simplified model can work EXACTLY like the real thing. Ask rocket scientists
Fortunately it doesn't have to be exactly like the real thing to be useful. Just ask machine learning scientists.
Given the prevalence of intelligence in nature using vastly different neurons I’m not sure if you even need to have an exact emulation of the real thing to achieve the same result.
No, that captures just the neuroanatomy. Not the properties like density of ion channels, type, value of the synapse and all the things we don't know yet.
I want the whole brain, not a republican.
Ultimately you need only a tiny fraction of that data to emulate the human brain.
Point for simulation theory.
Never seen Numenta talked about in the wild! Worked with them on a pattern recognition project in college and it was freaky similar to how toddlers learned about the world around them.
i mean they probably use vast amounts of data to learn how it all works.
Yes, humans kinda brute-forced intelligence with current assets - made it bigger (with some birthing issues) & more power hungry (with some cooling issues), but it mostly works.
“Google to shutter human brains”
Why anyone teams up with a company with its greatest achievement being a high score on the “I wish they hadn’t shut that down” list, is beyond my understanding.
Because almost nobody else has enough money for such research and governments won't pay for it because it's not very useful
I mean kubernetes, android, tensorflow, and the only OpenSource PDK for silicon that I know of.
They have a lot of bed rock contributions in the tech space.
Storage vendors are rolling their hands in delight while systems administrators, particularly backup admins are cringing at the thought.
A SUV full of tape might have the band with needed to restore from backup, but bless the tops that gotta load those tapes
How much of that is dead pixels?
So a 4k movie is 100 GB? 2 hour movie would make it 110 mbps. Insane bitrate even for h.254 imo
The movies as shown in cinema are ~600GB
4K Blu Rays encoded in H265 are usually on 100gb discs, so I can see where they're coming from
4K bluray can be up to 144 mbps, so that's reasonable.
I have LOTR directors cut on my server, haven't bothered reencoding it because I'm not super experienced with keeping hdr 10 going to h265 or equivalent. Return of the king alone is around 130 gigs across two files, jellyfin says its bitrate is about 70 mbps.
Titanic is only about 74 gigs