

Is an old raspberry pi useful for anything based on Linux?


Creating Asynchronous Applications with Virtual Threads Venkat Subramaniam BackEnd
Continuations: The magic behind virtual threads in Java by Balkrishna Rawool @ Spring I/O 2024



Efficient containers with Spring Boot 3, Java 21 and CDS by Sébastien Deleuze @ Spring I/O 2024
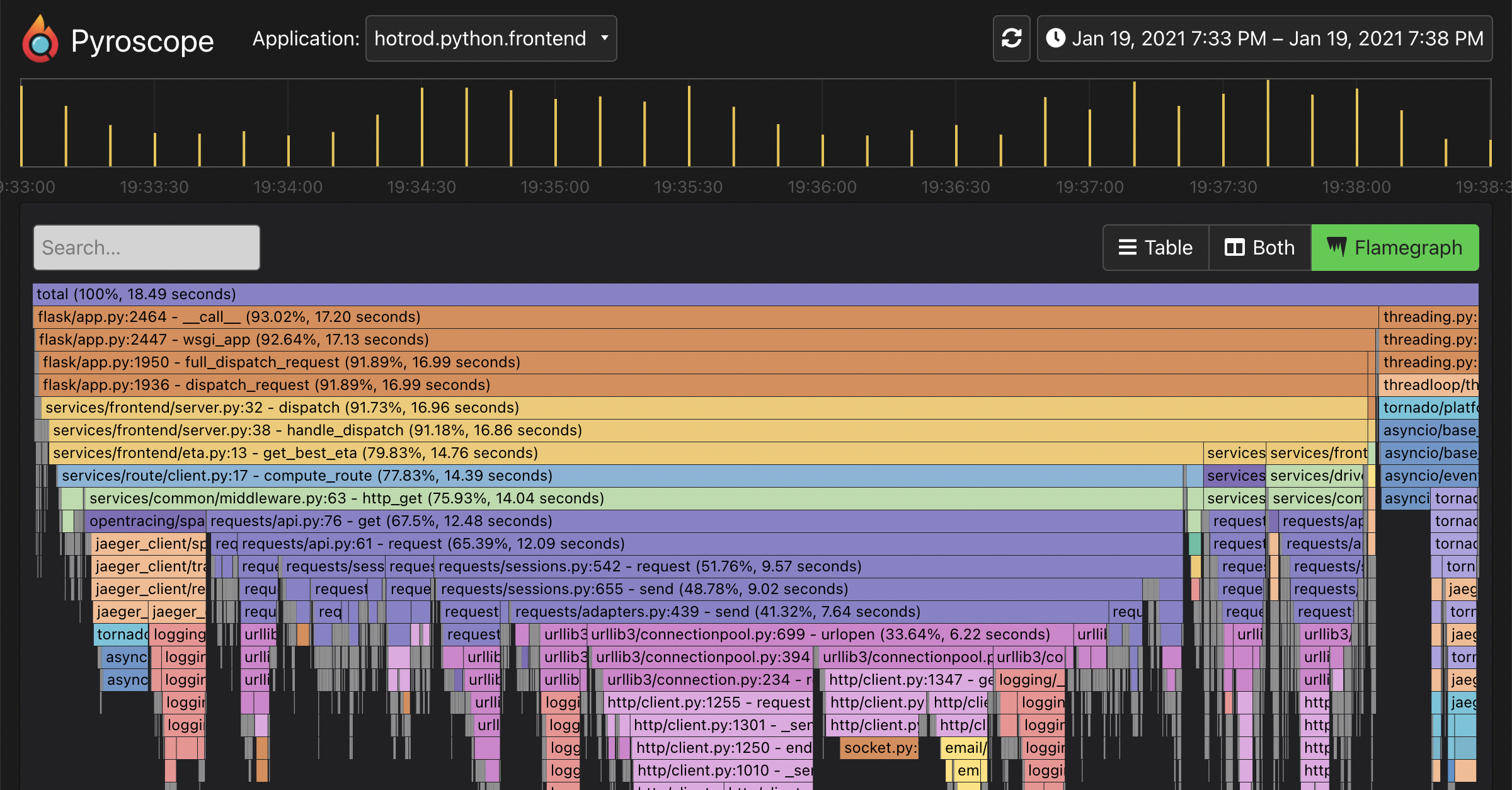
AI-Powered Flamegraph Interpreter in Grafana Pyroscope | Open Source Continuous Profiling Platform


Then try again today, and if it still doesn't work, you can set DNS profiles on your computer.