Distilling step-by-step: Outperforming larger language models with less training data and smaller model sizes
Distilling step-by-step: Outperforming larger language models with less training data and smaller model sizes

blog.research.google
Distilling step-by-step: Outperforming larger language models with less training data and smaller model sizes

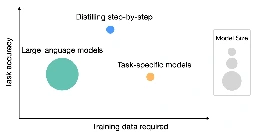
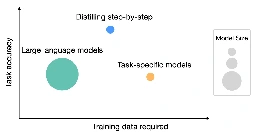

Woah this is pretty interesting stuff, I wonder how practical it is to do, I don't see a repo offering a script or anything so may be quite involved but looks promising. Anything to reduce size while maintaining performance is huge at this time
The code is available here:
https://github.com/google-research/distilling-step-by-step
Somehow this is even more confusing because that code hasn't been touched in 3 months, maybe just took them that long to validate? Will have to read through it, thanks!