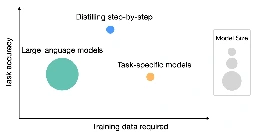
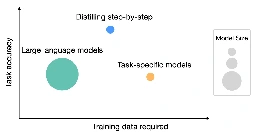
Outperforming LLMs with less training data and smaller model sizes
Outperforming LLMs with less training data and smaller model sizes

blog.research.google
Distilling step-by-step: Outperforming larger language models with less training data and smaller model sizes

There is a discussion on Hacker News, but feel free to comment here as well.